Elasticsearch自定义文档得分并排序
本文最后更新于:2022年4月1日 上午
大多数情况下,我们需要对查询结果排序,比方说按最新时间降序、按金额降序等。我们只需要对相应的字段 sort 即可。但有时候也会出现一些复杂的情况,比方说有A、B、C、D、E类数据,他想让你给这类数据重新定义优先级,按照B、E、D、A、C的顺序展示,并且每类数据内部按时间降序。然而最近我们也提出了一个类似这样的需求,查阅相关文档后,发现Elasticsearch里的function_socre函数可以实现这一功能, 遂将此学习内容做一个记录。
先来看看 function_score 是什么,它能做什么?根据官网的原话:
The
function_scoreallows you to modify the score of documents that are retrieved by a query.
function_score 允许你修改通过查询检索出来的文档的得分。
下面我们通过一些简单的例子来看看 function_score 怎么使用。
function_score 可以为所有文档生成一个随机分数:
1 | |
还可以组合不同的过滤条件,设置权重:
1 | |
如果
functions里的filter未给出,那么将会匹配所有文档,相当于"match_all":{}。
我们看看 function_score 为我们提供了哪些参数:
score_mode指定了该如何去合并每个文档生成的评分:score_mode 定义 multiply函数结果相乘(默认)sum函数结果相加avg函数结果的平均值first使用首个函数的结果做为最终结果max函数结果的最大值min函数结果的最小值boost_mode可以用来控制函数与查询评分_score合并后的结果:boost_mode 定义 multiply评分_score与函数值的乘积(默认)replace评分_score会被忽略,仅使用函数值sum评分_score与函数值之和avg评分_score与函数值的平均值max评分_score与函数值间的最大值min评分_score与函数值间的最小值min_score可以设置为期望分数的阈值,能够排出不符合特定分数阈值的文档。max_boost可以限制函数的最大效果,但是不会对最终的评分_score产生直接的影响。
function_score 还提供几种类型的评分函数:
script_score:脚本评分函数允许计算自定义查询的评分,脚本表达式需使用文档中的数值字段。查询的分数将与脚本评分的结果相乘,如果不想使用这种方式,可通过设置"boost_mode":"replace"来禁止。
1 | |
1 | |
weight:权重函数可以将评分与weight值相乘,weight的值是float类型。random_score:随机评分函数会产生一个0到1之间的分数,当种子feed值相同时,生成的随机结果是一致的。
1 | |
field_value_factor:通过使用文档中的某个字段来影响评分。如果这个字段有多个值,那么只有第一个值才被用来计算评分。
1 | |
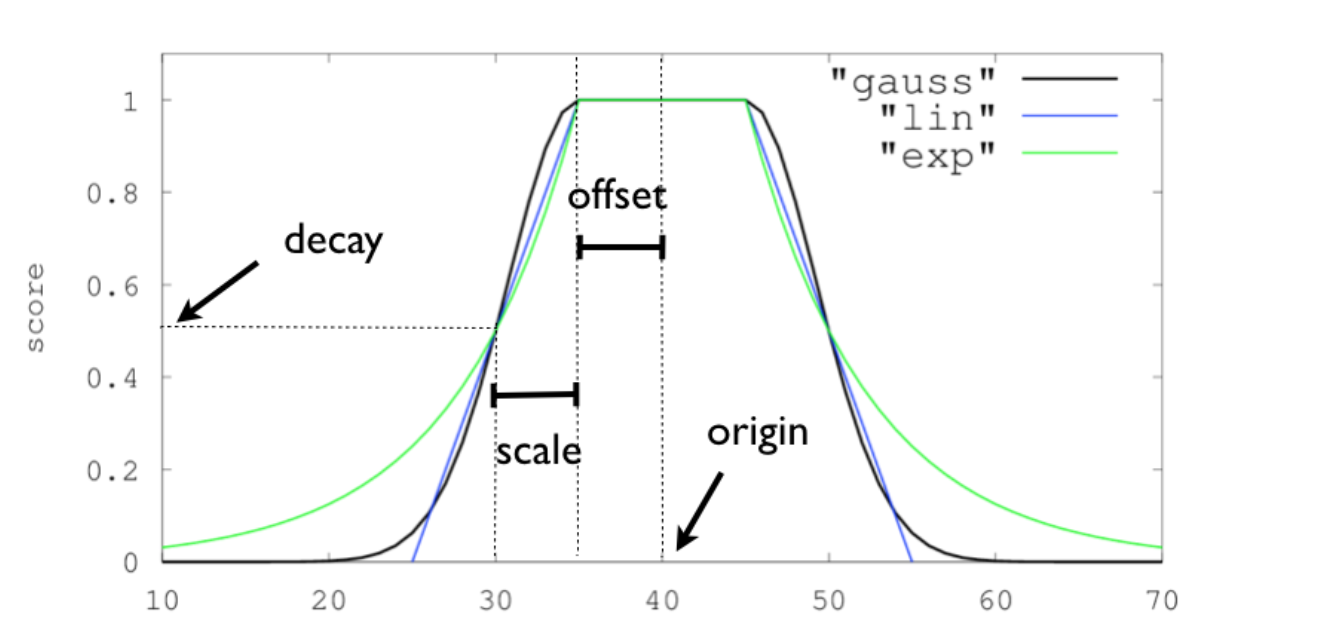
filed:文档中提取的字段。factor:字段值乘以的可选因子,默认是1。modifier:none,log,log1p,log2p,ln,ln1p,ln2p,square,sqrt,reciprocal。默认值是none.decay_functions:衰减函数的功能与范围查询类似,但它具有更平滑的边缘。衰减函数支持gauss、linear、exp中任意一种函数,并且都能接收以下参数:origin:中心点或字段可能的最佳值,落在原点origin上的文档评分_score为满分1.0。字段必须是数值、日期或地理坐标类型。scale:衰减率,一个文档从原点origin下落时,评分_score改变的速度。offset:以原点origin为中心点,为其设置一个非零的offset覆盖一个范围,而不只是单个原点。在范围-offset <= origin <= +offset内的所有评分_score都是1.0。decay:从原点origin衰减到scale所得的评分_score,默认是0.5。
1 | |
官方文档有这么一张图片说明了三个函数的衰减曲线形状:
以上就是 function_score 函数的大部分内容。现在我们来具体实现文章开头提到的一个需求。我准备了一份不同歌手的歌曲发行时间的测试数据,主要字段有歌手名name、歌曲名song、发行时间publishDate。
首先我们先按歌手名降序,发行时间升序,很容易能写出下面的DSL语句:
1 | |
现在我想按许冠杰、邓丽君、陈百强的顺序进行展示,并且各自的歌曲按发行时间升序,function_score 就体现出它的作用了:
1 | |
由于查询文档太长,我就不粘贴查询结果了。感兴趣的可以自己动手尝试尝试,如果需要测试数据,公众号回复 0816 即可获取相关文件。
相关链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-function-score-query.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/function-score-query.html
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!